


達摩院ModelScope開放中文語言理解及AI繪圖等模型
從自動生成文案到近期網絡流行的人工智能AI繪圖,AI在自然語言處理(natural language processing,NLP)及計算機視覺領域的應用越來越廣泛,而阿里巴巴達摩院的模型開源社區及創新平台ModelScope上,已經開放上述領域及語音、科學計算等模型庫及數據集,降低開發和使用人工智能模型的門檻,讓大學和中小企業都能使用人工智能作科研及商業用途。
其中在NLP領域,已經在ModelScope上開放的阿里巴巴通義大模型系列AliceMind(下稱「阿里通義AliceMind」),在11月底便憑藉高精準度的語文理解能力,成為中文語言理解測評基準項目CLUE面世3年來首個超越人類基準的參評AI模型。
阿里雲在11月初舉行的2022雲棲大會期間推出ModelScope平台,旨在降低人工智能模型的開發和使用門檻,平台包含達摩院在過去5年開發的逾300個「開箱即用」人工智能模型,涵蓋計算機視覺、自然語言處理和音頻等多個領域。
阿里通義AliceMind成為CLUE首個超越人類基準的AI模型
根據CLUE的排行榜於11月22日更新的成績,阿里通義AliceMind以86.685總分,成為排行榜面世近3年來首個超越人類基準線(86.678)的AI模型,反映AI中文語言理解水平達到新的高度。
目前阿里通義AliceMind的基礎模型,已經在達摩院的模型開源社區及創新平台ModelScope上開放。
CLUE是中文NLP的權威測評平台,從文本分類、閱讀理解、自然語言推理等9項任務中,考核參評AI模型的語言理解能力。CLUE總排行榜自2019年12月發佈至今近三年,一直吸引眾多中國內地頂尖NLP團隊的參與,儘管榜首位置多次易主,但參評AI模型一直未能超越人類基準成績。
為提升AI模型對詞語、句子以及語言整體的理解力,在預訓練階段,達摩院沿用超大規模模型訓練所使用的海量高質量中文文本,同時改善模型結構和訓練技術,例如使用激活函數GLU、字詞混合的大詞表等,獲得更強的文本建模能力;又例如使用StrongHold訓練加速技術縮短迭代周期、節約算力成本,進而獲得性能的顯著提升。在精調階段,面對文本分類、閱讀理解、自然語言推理等下游任務,達摩院採用遷移學習、數據增強、特徵增強等技術,進一步提升模型表現。
以CLUE榜單的CHID成語閱讀理解填空任務為例,該任務需要AI模型選出正確的成語進行填空。阿里通義AliceMind可通過海量文本數據的學習達到「博聞強識」的效果,在預訓練階段掌握選詞填空所依賴的語義理解能力,訓練成語數據的領域遷移。
在11月22日的測評結果中,阿里通義AliceMind在其中4項任務的表現超越人類的水平,並在總平均分首次超越人類基準線。
作為最早投入預訓練語言模型研究的團隊之一,達摩院研發阿里通義AliceMind體系,涵蓋預訓練模型、多語言預訓練模型、超大中文預訓練模型等,具備閱讀理解、機器翻譯、對話問答、文檔處理等多種能力。目前相關技術已應用於醫療、電商、法律等領域,在跨境電商領域,達摩院的機器翻譯系統能提供214種語言的互譯服務,每天為中國內地200萬中小商家翻譯上億文字,幫助中國國貨走向全世界。
達摩院開源以人為中心的視覺AI模型
計算機視覺是應用最廣泛的AI技術之一,從日常手機解鎖使用的人臉識別,再到火熱的產業前沿自動駕駛,視覺AI都大顯身手。
達摩院開放視覺智能負責人謝宣松表示:「視覺AI的潛能遠未得到充分發揮,窮盡我們這些研究者的力量,也只能覆蓋少數行業和場景,遠未能滿足全社會的需求。」他續指出,ModelScope已經全面開源達摩院研發的視覺AI模型,希望讓更多開發者來使用視覺AI,更期待AI能成為人類社會前進的動力之一。
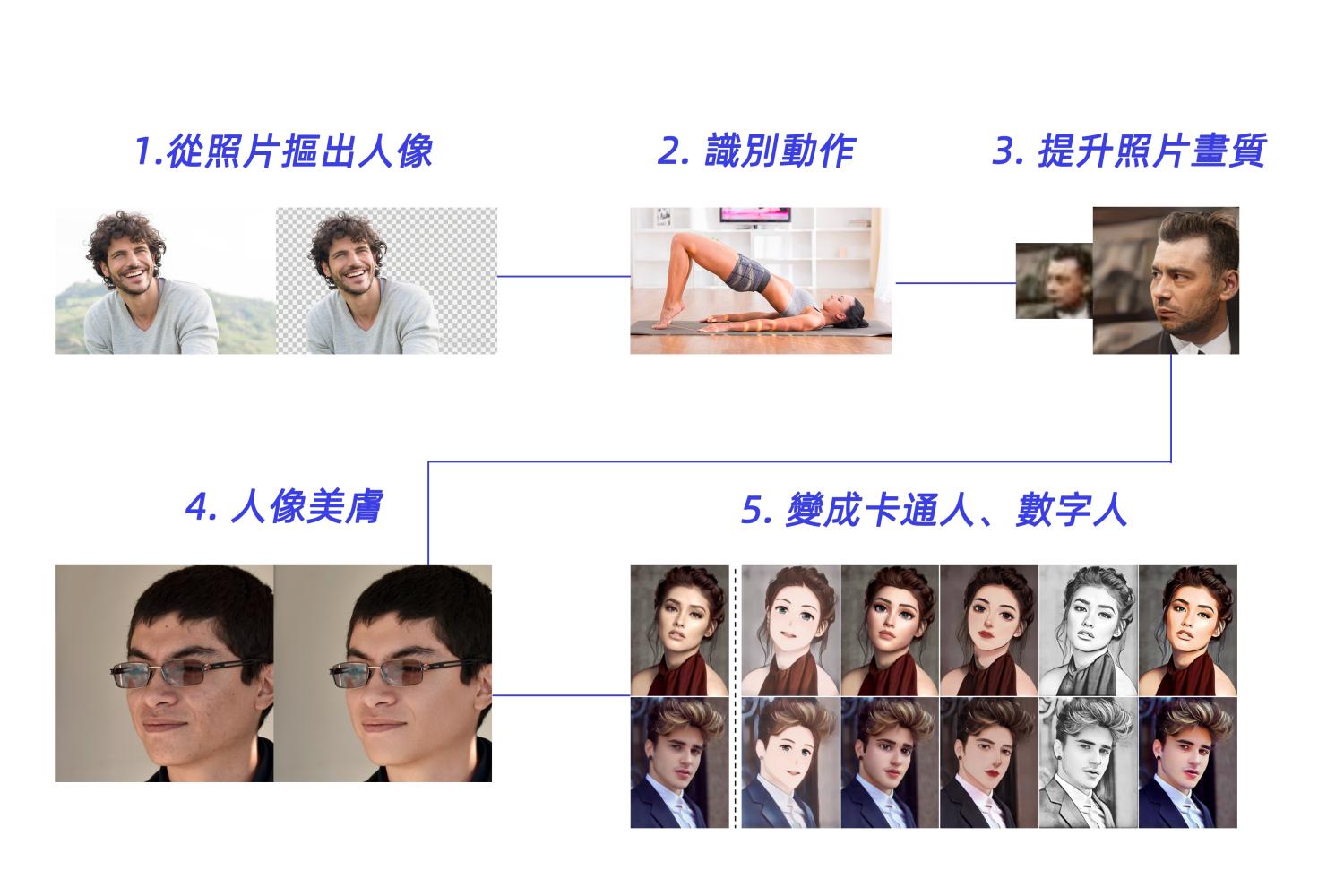
視覺AI技術覆蓋從感知理解、畫質增強到編輯生成等各方面。以單人照片為例,AI需要會先識別相中人有甚麼肢體動作、能否摳出圖像等,然後進一步探索照片質量如何、畫質能否變得更好、相中人能否變得更漂亮,甚至變成卡通人物或數字人等。
網絡常見的人像卡通化正是AI編輯生成的例子之一,ModelScope基於域校準圖像翻譯網絡DCT-Net(Domain-Calibrated Translation),採用「先全局特徵校準,再局部紋理轉換」的核心,利用百張小樣本風格數據,即可訓練得到輕量穩定的風格轉換器,實現高質量人像風格轉換效果。
試體驗:DCT-Net人像卡通化模型

拍攝不時因為環境、設備及人為操作等原因而導致圖像質量不佳,在畫質增強層面,ModelScope已經開放NAFNet 去噪模型,適用於很多應用的前置步驟,如智能手機圖像去噪、圖像去運動模糊等。該模型使用簡單的乘法操作替換激活函數,在不影響性能的情況下提升處理速度。
試體驗:NAFNet 去噪模型

除了圖片去噪去模糊,外界對圖片的細節紋理、色彩等質量問題會有更高的處理要求,ModelScope也開放專門的人像增強模型,對檢測到的圖片人像修復和增強,並對圖像中的非人像區域採用超分辨率技術,最終返回修復後的完整圖像。該模型能夠處理絕大多數複雜的真實降質,修復嚴重損傷的人像圖片。
試體驗:人像增強模型
事實上,達摩院在ModelScope面世前已經率先開放API形態的視覺AI服務,通過公共雲平台對AI開發者通過「視覺智能開放平台」提供一站式視覺線上服務,開放超200個API並涵蓋基礎視覺、行業視覺等方面。
謝宣松認為,從開放視覺平台到ModelScope社區,意味著達摩院視覺AI的開放邁出更大一步,藉以滿足千行百業對視覺AI的需求,促進視覺AI的生態發展。
立即訂閱阿里足跡,緊貼阿里巴巴集團最新發展動向,通過新聞故事及專題文章了解創新科技、電子商務及智能物流等新興議題的嶄新趨勢。


分享